There has been a bit of debate on Twitter about this post at The Political Scientist, which argues that the National’s rise in the polls is merely the result of Labour voters switching to “undecided” and reducing the denominator. There were also a few requests for an explanation, and Thomas at StatsChat has obliged here (also, I stole his title). I have a few points I want to add or expand on.
Firstly, as an aside, many of the mistakes are the same as those made in this post on Kiwiblog which argues based on correlation coefficients that in 2011 it was mainly National voters who stayed home, not Labour voters.
Secondly, we don’t actually know the number of undecided voters. As pointed out in comments on the StatsChat rebuttal many of the raw numbers are weighted by demographics, probability of voting, and others (whether or not they also have a cellphone?).
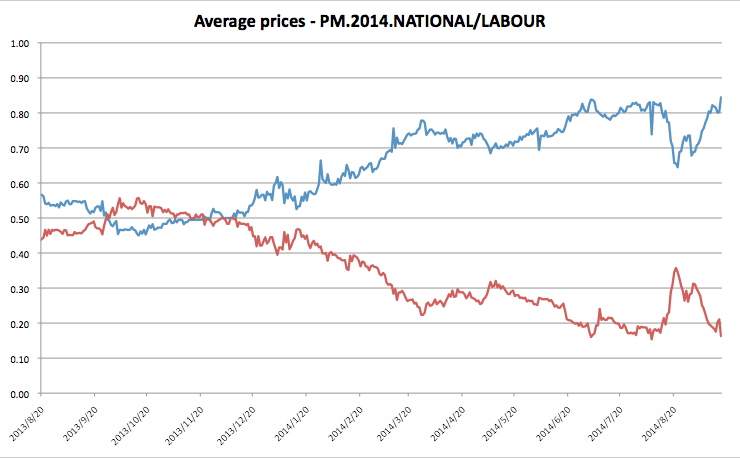
Thirdly, the results for the correlation coefficients are very susceptible to the number of polls. On first read this particular table from The Political Scientist stood out:

Correlation coefficients, from The Political Scientist.
The table shows the correlation coefficients with the undecided vote for four parties for all nine Fairfax polls from July 2012 to June 2014 (top), and for only eight polls, with the June 2014 poll results excluded (bottom). You can see that the correlation coefficient for National changes from 0.7 to 0.3 with the addition of a single poll! Obviously the results aren’t particularly robust, and that is equally as true for the other three parties as well, even if they just happened to show smaller changes in the table above.
Taking this a step further, it should be reasonably obvious that you can’t trust estimates of correlation coefficients based on a small number of data points. When you have only two data points to work with you must get a correlation coefficient of 1 even if there is no actual correlation between the things you are measuring, because for any two given points it is possible to draw a straight line that passes through both of them (or, rephrasing, two points define a straight line). Adding more data points will move your estimate of the correlation coefficient closer to the true value, but with a small number of polls you can never be very confident.
As another aside, always be suspicious when you see results quoted to a large number of significant figures. There’s nothing wrong with it in principle, but it raises the question of how accurate they really are. In this particular case, if the addition of a single poll moves National’s coefficient from 0.7 to 0.3 then there’s no point quoting more than one decimal place, if at all.
Fourthly, there seems to be confusion between different coefficients.
Thomas covers this point, the difference between correlation coefficients and regression coefficients, in paragraphs 2-3.
More intuitively though, the correlation coefficients shown in the table above between NZ First and undecided voters (0.8) is almost that same as that for Labour’s. Does the drop in NZ First support cause the increase in undecided voters? In the last two year the number of respondents supporting NZ First fell from 32 to 24 (see linked table below), while the number of undecided respondents went from about 110 to 230. Would you argue that the 8 former supporters per 1000 lost by NZ First turned into 220 new undecided voters? Of course not!

Poll results, and estimated number of respondents, from The Political Scientist.
You may argue that the real evidence is that the number of supporters lost by labour is (roughly) equal to the increase in the number of respondents who are undecided, and that correlation coefficients have nothing to do with it. And that’s fine. But then why bother publishing the correlation coefficients at all?
Fifthly, correlation does not imply causation (see also, xkcd). When dealing with correlation effects you have to be very careful to avoid false causation. Even assuming the changes aren’t just a statstical fluctuation we still can’t say whether Labour voters are really becoming undecided. As Thomas says
You could fit the data just as well by saying that Labour voters have switched to National and National voters have switched to Undecided by the same amount — this produces the same counts, but has different political implications.
If you’re a frequentist then Thomas’ alternative explanation is just as convincing. If you’re Beysian then now might be a good time to break out Occam’s Razor and say that you thought that Labour voters were switching to undecided anyway, so you believe the first hypothesis. Which is fine. But in that case was there any value in the analysis?
The only way to figure out what it really going on is to do a longitudinal study where you use the same sample of voters for each poll.
Sixthly, in their conclusion The Political Scientist says
Without taking into account the level of the undecided vote this presents a misleading picture of how many voting age New Zealanders support each party.
Of course, by limiting reporting only to those who have declared party support and are likely to vote the reporting may very well reflect what could happen in an election.
This is sort of hedging both ways. If the point of the Fairfax poll is to gauge support and/or try and predict the results of an election “if it were held today”, then the pollsters must do something with the undecided voters. Unless you have evidence that they break differently than for decided voters (which could be the case), it seems sensible to just ignore them when publishing the headline results. It’s not “a very misleading picture” at all.
Bonus: check out this excellent diagram from Wikipedia showing the differences between regression coefficients and correlation coefficients. All the graphs in the middle row (except the centre) have the same absolute correlation coefficients.

Correlation coefficients.